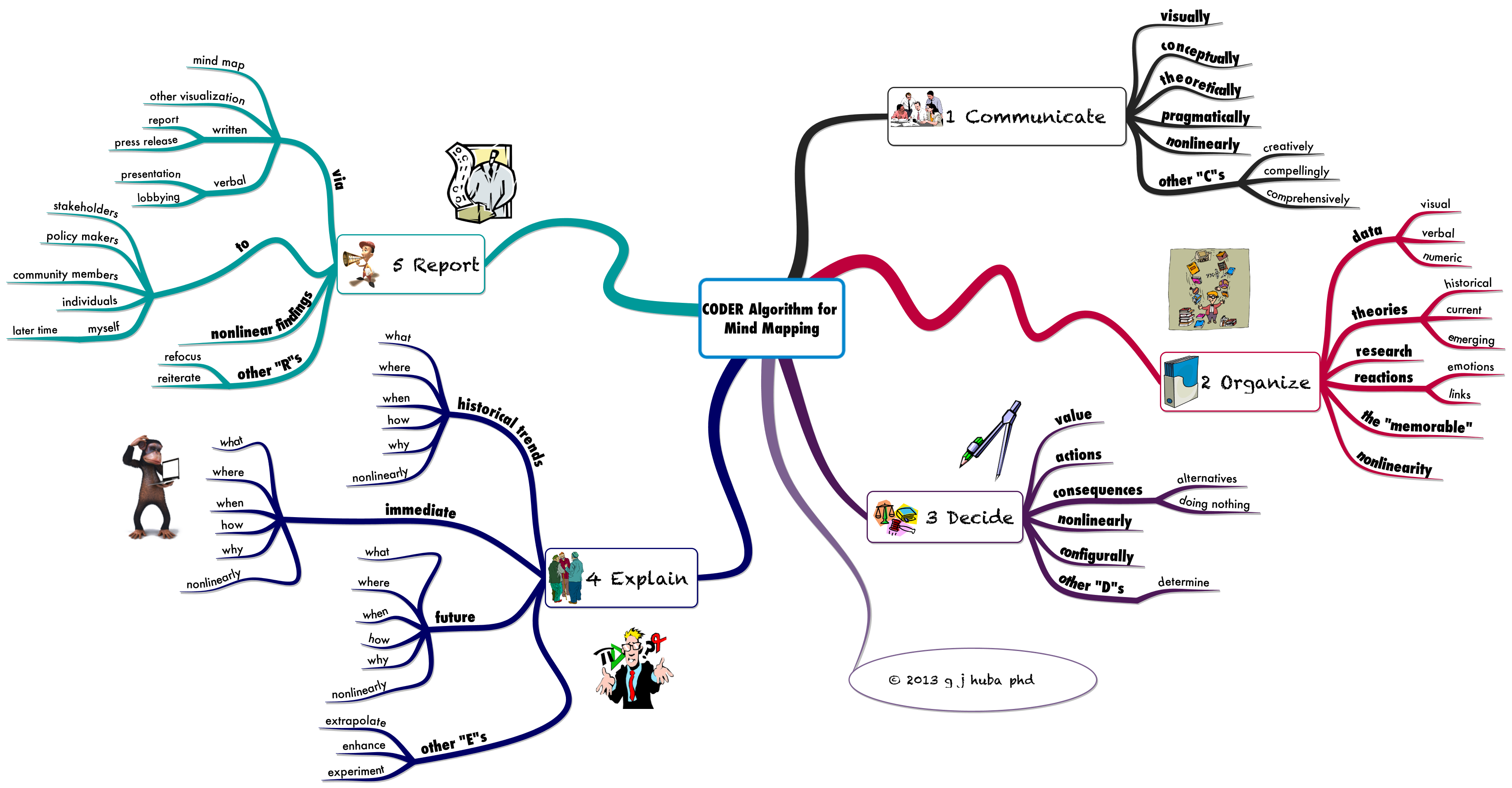
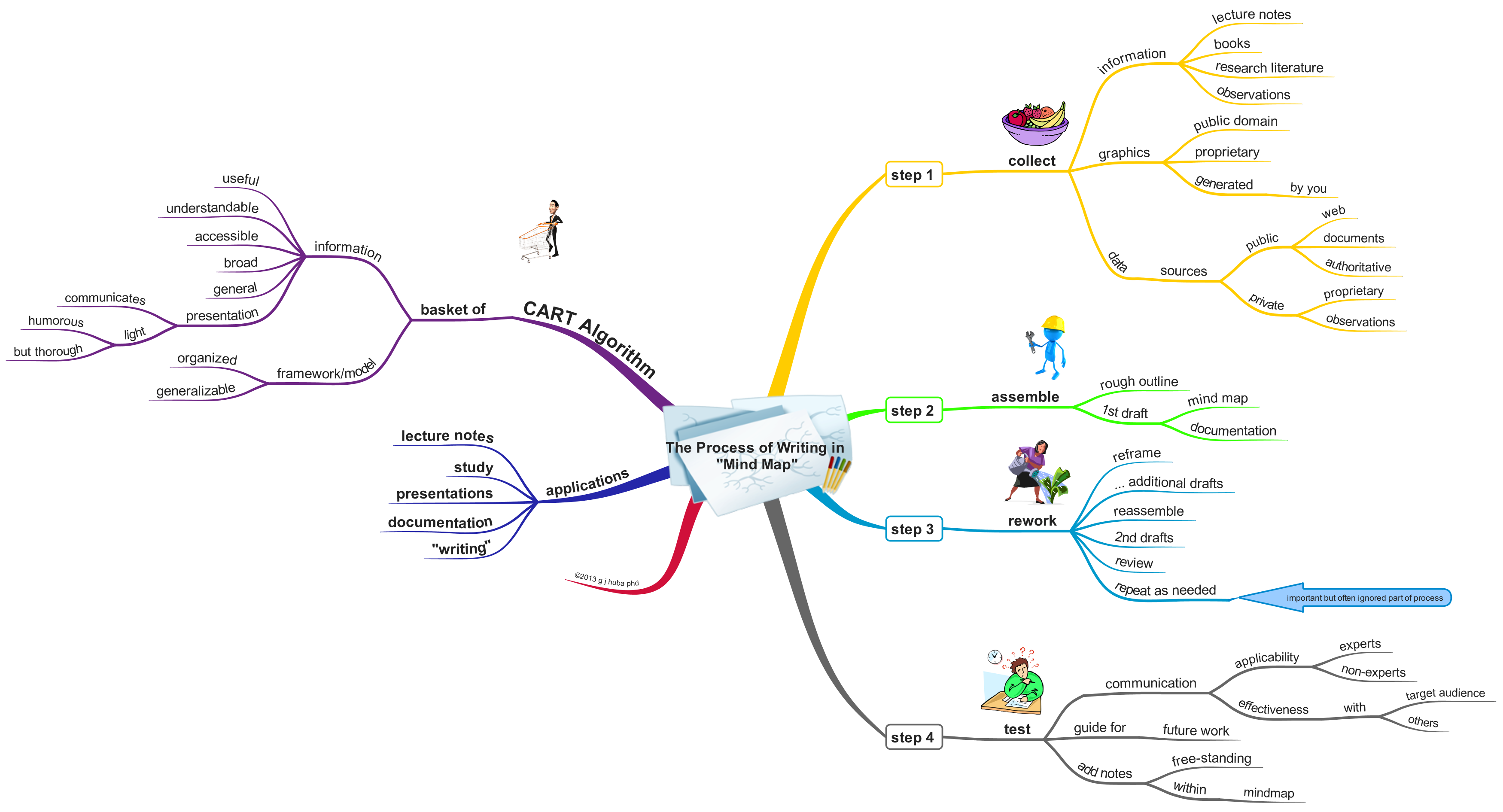
I consider John W. Tukey to be the King of Little Data. Give him a couple of colored pencils, the back of a used envelope, and some data and he could bring insight to what you were looking at by using graphic displays, eliminating “bad” data, weighting the findings, and providing charts that would allow you to explain what you were seeing to those who had never been trained in technical fields.
I consider John W. Tukey to be the King of Little Data. Give him a couple of colored pencils, the back of a used envelope, and some data and he could bring insight to what you were looking at by using graphic displays, eliminating “bad” data, weighting the findings, and providing charts that would allow you to explain what you were seeing to those who had never been trained in technical fields.
Tukey’s approach to “bad data” (outliers, miscodings, logical inconsistency) and downweighting data points which probably make little sense is what will save the Big Data Scientists from themselves by eliminating the likelihood that a few stupid datapoints (like those I enter into online survey databases when I want to screw them up to protect privacy) will strongly bias group findings. Medians are preferable to means most of the time; unit weighting is often to be preferred over seeing too much in the data and then using optimal (maximum likelihood, generalized least squares) data-fit weighting to further distort it.
Few remember that Tukey was also the King of Big Data. At the beginning of his career, Tukey developed a technique called the Fast Fourier Transform or FFT that permitted fairly slow computing equipment to extract key information from very complex analog data and then compress the information into a smaller digital form that would retain much of the information but not unnecessary detail. The ability to compress the data and then move it over a fairly primitive data transmission system (copper wires) made long distance telephone communications feasible. And later, the same method made cellular communications possible.
Hhmm. More than 50 years ago, Tukey pioneered the view that the way to use “sloppy” big data was to distill the necessary information from it in an imprecise but robust way rather than pretending the data were better because they were bigger and erroneously supported over-fitting statistical models.
Hopefully it will not take another 50 years for the Big Data folks to recognize that trillions of data points may hide the truth and that the solution is to pass out some red and blue pencils and used envelopes. Tukey knew that 50 years ago.
All it “costs” to adopt Tukey’s methods is a little commonsense.
Hhmm, maybe the Tukey approach is not so feasible. Big Data proponents at the current time seem to lack in aggregate the amount of commonsense necessary to implement Tukey’s methods.
Turn off the computers in third grade, pass out the pencils, and let’s teach the next generation not to worship Big Data and developing statistical models seemingly far more precise than the data.